[AI] RAG는 검색 기능이 아니라 흐름이다
![[AI] RAG는 검색 기능이 아니라 흐름이다](https://firebasestorage.googleapis.com/v0/b/cruz-lab.firebasestorage.app/o/images%2Fheroes%2F2026%2F04%2Frag-1777286447984-z5rhd2.jpg?alt=media&token=ca554378-106e-45b1-9190-c050591c50de)
RAG를 처음 보면 보통 이렇게 이해한다.
"문서 넣고 검색해서 LLM에 붙이는 거 아냐?"
맞다. 그런데 막상 흐름을 따라가보면, 문제는 검색 하나보다 전체 단계를 어떻게 이어 붙이느냐 쪽에 더 가깝다.

RAG를 설명할 때는 보통 검색부터 떠올린다.
그런데 실제로는 거기 전부터 이미 갈리기 시작한다.
질문을 잘못 해석하면 엉뚱한 문서를 찾고,
청킹이 어색하면 검색은 맞아도 문맥이 반쯤 잘린다.
검색 결과를 그대로 넣으면 또 답변이 미묘하게 빗나간다.
그래서 RAG는 검색 기능 하나라기보다,
질문을 받아서 근거 있는 답으로 바꾸는 여러 단계를 묶어놓은 파이프라인에 더 가깝다.
RAG의 시작점은 벡터 DB가 아니라 질문이다
RAG 얘기를 하면 금방 임베딩, 벡터 DB, 검색 정확도 쪽으로 넘어간다.
그런데 실제로는 그 전에 한 번 더 봐야 할 게 있다.
애초에 이 질문이 검색이 필요한 질문인가?
이걸 먼저 안 가르면 뒤가 애매해진다.
문서 검색이 필요한 질문인데 생성처럼 다루면 문서를 안 보고 답하려 들고,
반대로 검색이 굳이 필요 없는 질문인데 RAG를 붙이면 흐름만 괜히 무거워진다.
사용자 질문이 들어오면 먼저 이런 걸 본다.
- 이 질문은 사실 검색이 필요한가?
- 이전 대화 문맥을 붙여야 하나?
- 특정 문서 집합만 봐야 하나?
- 키워드 매칭이 더 유리한가, 의미 검색이 더 유리한가?
예를 들어 "환불 정책이 뭐야?" 같은 질문은 문서 검색이 잘 맞는다.
반면 "이 문서 스타일을 더 읽기 쉽게 고쳐줘"는 검색보다 생성 작업에 가깝다.
RAG는 질문이 들어왔다고 자동으로 붙이면 되는 기능이 아니다.
먼저 이 질문이 검색형인지부터 가르는 편이 낫다.
청킹을 잘못하면 검색이 아니라 문서 찢기가 된다
문서는 길다.
그래서 보통 chunk로 나눠 저장한다.
문제는 이 청킹이 생각보다 까다롭다는 점이다.
너무 크게 자르면?
- 관련 없는 문장이 같이 들어온다
- 검색은 맞았는데 답변에 불필요한 잡음이 많아진다
너무 잘게 자르면?
- 문맥이 사라진다
- 검색은 맞았는데 읽어보면 무슨 말인지 모른다
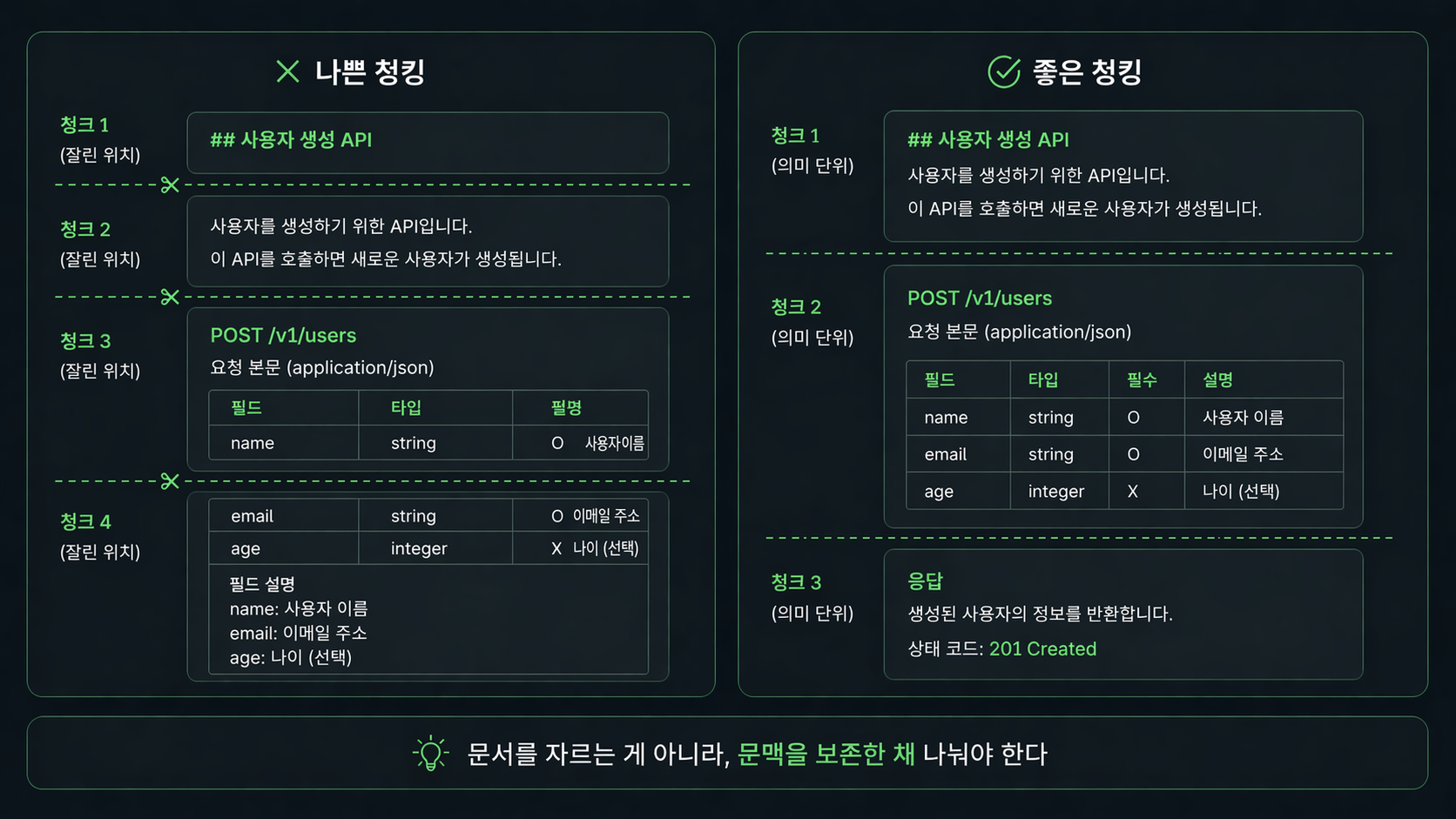
실제로는 이런 식으로 제목, 설명, 표가 따로 떨어지는 순간부터 결과가 이상해지기 시작한다.
검색은 맞았는데 정작 답변에 필요한 문맥은 반쪽만 들어오는 식이다.
그래서 결국은 이런 기준으로 보게 된다.
- 문서 구조를 최대한 보존하면서
- 한 chunk 안에서 의미가 끊기지 않도록
- 겹침(overlap)은 조금 두되 과하지 않게
특히 제목, 소제목, 표, 코드블록은 일반 문단보다 더 조심해서 잘라야 한다.
예를 들어 API 문서라면 함수 설명과 파라미터 표가 한 덩어리로 남아야 한다.
둘이 갈라지면 검색은 걸려도, 답변은 꼭 반쪽짜리처럼 나온다.
임베딩은 저장 단계의 번역기다
문서를 chunk로 나눴다면, 이제 각 chunk를 임베딩 벡터로 바꾼다.
이걸 좀 덜 딱딱하게 말하면,
문서를 의미 기준으로 다시 찾을 수 있게 바꿔두는 과정에 가깝다.
문자 그대로 저장하면 키워드 검색은 쉽다.
하지만 "비슷한 의미"를 찾는 데는 약하다.
임베딩은 이걸 보완한다.
예를 들어 질문이 "로그인 유지가 왜 풀려요?"인데 문서에는 "세션 만료 정책"이라고 적혀 있을 수 있다.
단어만 보면 전혀 안 맞아 보이는데, 의미 기준으로 보면 둘이 생각보다 가까운 경우가 있다.
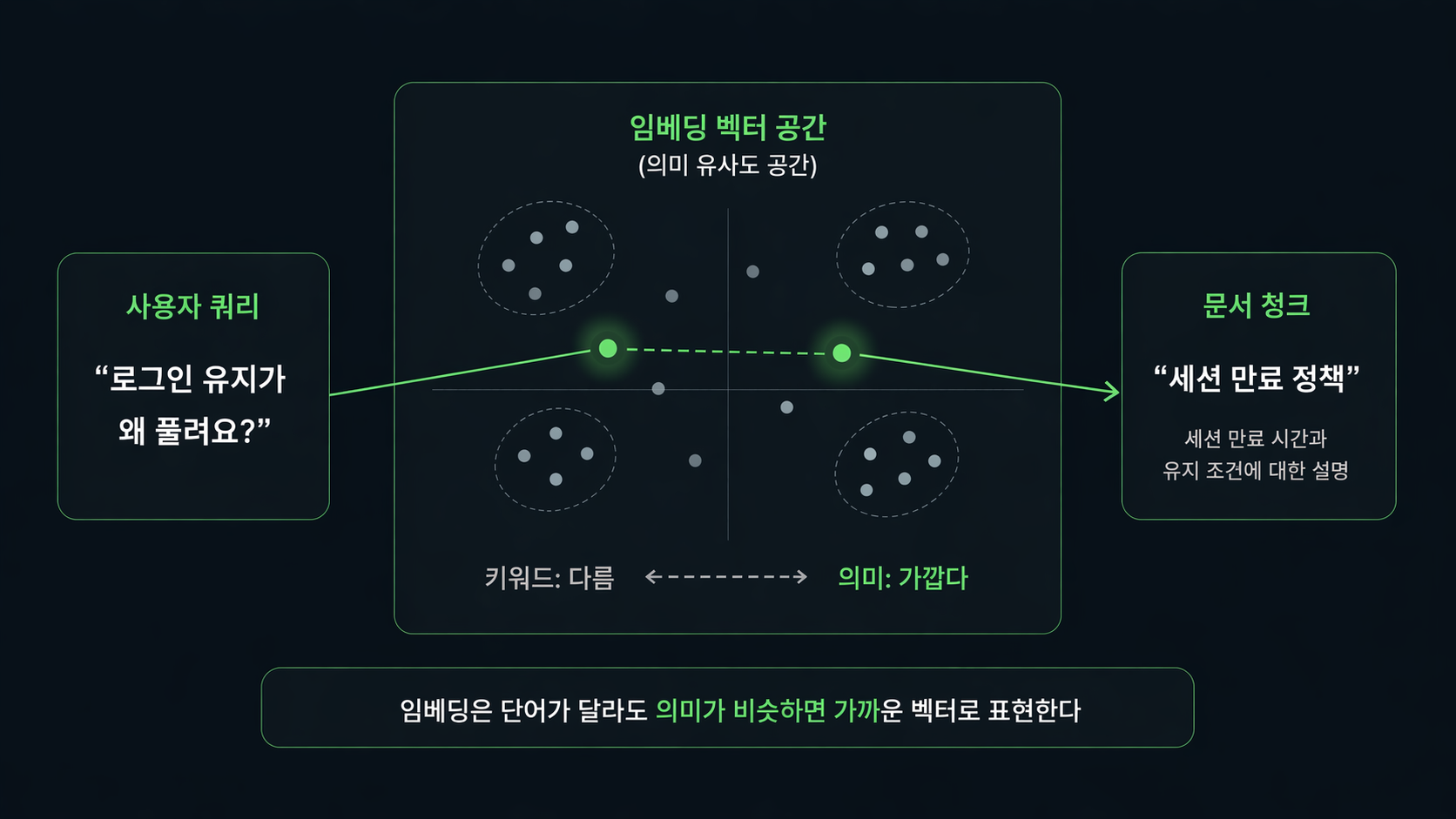
이럴 때 키워드 검색만으로는 놓치기 쉽고, 임베딩이 들어가면 비로소 연결되는 경우가 생긴다.
물론 임베딩이 만능은 아니다.
- 숫자
- 정확한 버전명
- 코드 심볼
- 고유명사
이런 건 여전히 키워드 검색이 더 강한 경우가 많다.
그래서 실무에서는 벡터 검색만 단독으로 쓰기보다, 키워드 검색과 섞는 하이브리드 방식을 더 자주 보게 된다.
벡터 DB는 저장소가 아니라 검색 엔진 쪽에 가깝다
임베딩한 chunk는 보통 벡터 DB에 넣는다.
여기서 더 중요한 건 "벡터 DB를 썼다" 자체보다,
문서를 어떤 메타데이터와 같이 넣어뒀느냐 쪽이다.
예를 들면 이런 정보들이 같이 있으면 좋다.
- 문서 ID
- 제목
- 섹션
- 버전
- 작성일
- 접근 권한
- 원문 URL
이 메타데이터가 있어야 검색 후 필터링이 가능하다.
예를 들어 최신 버전 문서만 보게 하거나, 특정 프로젝트 문서만 조회하게 만들 수 있다.
RAG 품질은 임베딩 모델 하나만으로 결정되지 않는다.
막상 운영 쪽으로 가면, 메타데이터 설계가 더 크게 체감될 때도 많다.
검색이 끝이 아니다. 재정렬과 컨텍스트 조립이 더 중요하다
초반 구현이 여기서 자주 무너진다.
"Top K 검색 결과 5개 뽑았으니 그대로 LLM에 넣자."
이렇게 가면 생각보다 결과가 들쭉날쭉하다.
왜냐하면 검색 결과 5개가 다 "어느 정도 관련"은 있지만,
질문에 정확히 필요한 순서로 정렬돼 있지는 않기 때문이다.
그래서 중간에 보통 한 번 더 걸러준다.

처음 검색 결과만 보면 "대충 맞는 것 같은데?" 싶다.
그런데 실제 답변에 넣어보면, 위에 있어야 할 문서와 아래로 빠져야 할 문서가 은근 다르다.
그래서 보통 이런 작업이 한 번 더 들어간다.
- reranker로 다시 정렬하거나
- 질문 유형별로 특정 필드를 우선하거나
- 너무 비슷한 chunk는 중복 제거하고
- 서로 이어지는 문맥은 합쳐준다
그리고 그다음이 더 중요하다.
LLM에 넘길 컨텍스트를 사람이 읽어도 이해될 형태로 조립해야 한다.
그냥 붙여 넣는다고 끝나는 게 아니라,
- 어떤 문서에서 가져왔는지
- 어떤 순서로 읽어야 하는지
- 질문과 직접 관련된 부분이 무엇인지
를 어느 정도 구조화해서 넘기는 편이 훨씬 낫다.
마지막 단계는 생성이 아니라 "근거 있는 생성"이다
이제야 LLM 차례다.
여기서 프롬프트가 중요해진다.
RAG 프롬프트에서 자주 필요한 조건은 이런 것들이다.
- 제공된 문맥 안에서만 답할 것
- 근거가 부족하면 모른다고 말할 것
- 출처를 같이 표시할 것
- 문서 간 충돌이 있으면 최신 문서를 우선할 것

결국 여기서 필요한 건 "그럴듯하게 말해줘"가 아니다.
가져온 문맥 안에서, 어디까지 말할 수 있는지만 답하게 만드는 쪽에 더 가깝다.
이 단계를 잘 설계할수록 hallucination도 줄어든다.
그래서 RAG를 잘 만들려면 뭘 봐야 할까?
내가 먼저 보는 건 이런 것들이다.
- 질문이 정말 검색이 필요한 질문인가?
- 청킹이 문맥을 잘 보존하는가?
- 임베딩만 믿지 말고 키워드 검색도 필요한가?
- 메타데이터 필터링이 충분한가?
- 검색 결과를 그대로 넣지 않고 다시 정렬하는가?
- LLM에게 근거 중심으로 답하게 시키고 있는가?
여기서 하나라도 약하면 전체 품질이 금방 흔들린다.
RAG는 벡터 DB 하나 도입했다고 끝나는 기능이 아니다.
질문 해석부터 답변 생성까지 이어지는 흐름 전체의 설계 문제다.
마무리
RAG를 설명할 때 벡터 DB만 앞세우면, 정작 중요한 걸 놓치기 쉽다.
실제로는 이런 순서에 가깝다.
- 질문을 해석하고
- 문서를 적절히 자르고
- 검색 가능한 표현으로 바꾸고
- 관련 조각을 찾고
- 다시 정렬하고
- LLM이 근거 기반으로 답하도록 만든다
즉, RAG는 검색 기능이 아니다.
질문을 근거 있는 답변으로 바꾸는 파이프라인이다.
그래서 RAG를 잘 만들고 싶다면, 모델 하나보다 흐름 전체를 먼저 보는 편이 맞다.